

Alfontso Mujika
Noizean behin, galdera hori plazaratzen da. Borondate onarekin egindako galdera izaten da, baina galdera inozoa da. Bere horretan erantzun zehatzik ez duen galdera da, baina hor tematuko zaizkizu.
Gaztelaniak eta frantsesak baino askoz gutxiago? jarraituko dute.
Ez dago jakiterik erantzuten baduzu, berehala esango dizute: Begiratu hiztegian. Han jarriko du.
Eta hor hasi behar duzu azaltzen badirela hiztegi mota asko, hiztegiek ez dituztela hitz guztiak jasotzen, badirela hitz asko jada erabiltzen ez direnak eta badirela… Azkenean, kopuru bat eman beharko diezu, lasai utziko badituzu.
Lasai uzteaz gainera pozik ere utzi nahi badituzu, datu hau eman diezaiekezu:
Orotariko Euskal Hiztegiak (OEH) 125.000 sarrera ditu.
Baina zintzo jokatu nahi baduzu, zerbait gehiago ere esan beharko diezu. OEHn sarrera diren hitz asko eta asko (Zenbat? Erdiak, beharbada) sarrera baten aldaera grafikoak dira. Euskararen grafia-batasuna bart gaueko kontua denez, normala da hitz batek aldaera asko izatea. Adibidez, OEHko sarrera hauek guztiak ez dira benetako sarrerak, sarrera baten aldaerak baizik:
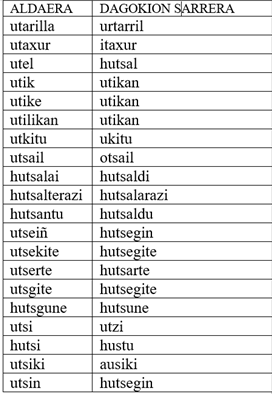
Beraz, baliteke OEHn dauden benetako sarrerak 70.000ra ere ez iristea, garai guztietako eta euskalki guztietako hitzak izan arren. Baina, bestalde, OEHn ageri diren hitzak 1970eko hamarkada arteko testuetatik jasotakoak besterik ez dira. Azken berrogei urteotan, euskara idatziaren historiako aurreko guztietan baino askoz gehiago idatzi da, eta, jakina, askoz hitz gehiago erabili dira eta erabiltzen dira.
Gatozen gaur egungo lanetara. Euskaltzaindiaren Hiztegi Batua etengabe handitzen ari da, amaitu gabeko proiektua baita; azken bertsioa aurtengoa da, eta 37.874 sarrera ditu (benetako sarrerak; hau da, azpisarrerak kontuan hartu gabe. Adibidez: abade sarrera da, baina abade egin, abade-etxe eta abade nagusi azpisarrerak dira).
Har dezagun hiztegi elebidun moderno handi bat. Adibidez, Elhuyar hiztegi elebiduna (euskara/gaztelania). Azken edizioak 90.000 sarrera inguru ditu; erdiak inguru, euskarazko sarrerak: 45.000. Eta izen bereziak kenduta, euskarazko 42.000 hitz arrunt inguru izango ditu.
Eta 42.000 sarrera asko dira? Gutxi dira? Begiratu dezagun auzo-hizkuntzetara.
Frantsesez, Dictionnaire de l’Académie française obraren 9. argitalpenak 60.000 sarrera izango ditu amaitzen denean (“resservir” sarreran zihoan 2016ko apirilean). 8. argitalpena 1935ean argitaratu zen, 35.000 sarrerarekin. Hala ere, hiztegi berezia da, ez baitu gaur egungo benetako frantsesa islatzen. Frantsesezko hiztegi deskribatzaile erabilienak Le Petit Robert eta Le Petit Larousse dira. Lehenengoak 60.000 sarrera ditu, eta bigarrenak 59.000.
Gaztelaniaz, erreferentzia nagusia DRAE da, Espainiako akademiaren hiztegia. Azken edizioak 93.111 sarrera ditu; haietatik, 30.000 sarrera inguru amerikanismoak dira.
Eta beste hizkuntza batzuetan? Oxford English Dictionary obrak, adibidez, 300.000 sarreratik gora ditu. Eta nederlanderazko Woordenboek der Nederlandsche Taal obrak, berriz, 450.000 inguru. Baina hiztegi historikoak dira biak, hau da, ez dira gaur egungo ingelesaren edo nederlanderaren benetako isla, garai guztietako hitzak baitituzte.
Itzul gaitezen euskarara. Euskarak zenbat hitz dituen jakiteko modu bat hiztegiei erreparatzea da, baina, gaur egun, bada beste aukera bat: corpusak. Corpusek testu-masa handiak jasotzen dituzte eta informatikoki lematizatzen dituzte (adibidez, testuetan ageri diren etxea, etxean, etxetik… hitzetatik lema bakarra ateratzen da: etxe). Baina, lema ontzat emateko, hiztegi batekin konparatu behar dira hitz guztiak (hiztegietan, lemak dira sarrera); hau da, corpusak bere hiztegiarekin kontrastatu behar ditu lema horiek guztiak (adibidez, aurreko adibideko etxe benetako lema bat dela jakiteko, bere hiztegiarekin kontrastatu behar du corpusak, eta hiztegi horrek esango dio etxe badela euskal hitz bat. Baina fein hitza aurkitzen badu, kontrastatzean, hiztegiak esan behar dio hori ez dela euskal hitza).
Zer gertatzen da, ordea, kontrasterako hiztegian ez dagoen hitz horrekin? Sinplifikatuz, corpusgileak hiru aukera nagusi ditu: automatikoki baztertu, automatikoki onartu edo banan-banan aztertu eta kasu bakoitzean erabaki (azken aukera hori garestia da, jakina).
Hori alde batera utzita, pentsatu behar da corpusak zenbat eta handiagoak izan hainbat lema gehiago lortuko dituela. Hala da, baina corpus baten hitz-kopuruaren eta lema-kopuruaren arteko erlazioa ez da lineala, asintotikoa baizik: corpusetan, zenbat eta hitz gehiago izan, hainbat txikiagoa da lema-kopurua / corpuseko hitz-kopurua ratioa; hau da, gero eta hitz gehiago behar dira lema berri bat aurkitzeko. Adibidez, egun bateko Berria egunkaria hartu eta hitz guztiak (H1) aterako bagenitu, L1 lema (L1 hitz desberdin, alegia) lortuko genituzke corpus horretatik. Hurrengo eguneko Berria egunkaria berriro hustuko bagenu (H2 hitz), L2 lema lortuko genituzke. Bi egunetako Berriarekin osatutako corpusak egun bakarreko corpusak halako bi hitz izango luke (H1 + H2), baina lema-kopurua ez litzateke L1 + L2 izango, lema asko eta asko errepikatuta egongo liratekeelako.
 Nolanahi ere, corpusek (orekatuak badira eta informatikoki ondo tratatuta badaude) aski ongi eman dezakete hizkuntza baten hitz-kopuruaren berri.
Nolanahi ere, corpusek (orekatuak badira eta informatikoki ondo tratatuta badaude) aski ongi eman dezakete hizkuntza baten hitz-kopuruaren berri.
Gaur egungo euskararen bi corpusik handienak Elhuyar Fundazioaren corpus elebakarra (CE) (124.625.420 testu-hitz) eta EHUren Egungo Testuen Corpusa (ETC) dira (269.200.000 testu-hitz).
CE corpusak 78.475 lema ditu[1], baina, izen bereziak kenduta, 75.000 lema inguru izango ditu. Eta kontrastatutako lemak dira guztiak; hau da, kontrasterako erabilitako hiztegian ez daudenak baztertuta daude.
ETC corpusak 91.884 lema ditu. Ez dakit nolakoak diren corpus horren tripak, baina benetako lemak edo lema «homologagarriak» gutxiago dira. Izan ere, corpus horrek lematzat hartzen dituen hitz batzuk nekez onar litezke euskal hiztegi batean.
Adibidez, badare (badaude / bada ere behar lukeen tokian), newspeak, fein, chinchorro, shave, whiteout, caballero, cuatrolatas, abecedario, acidophilum…
Beste batzuk, berriz, badira euskal hitzak, nahiz nekez sartuko liratekeen sarrera gisa euskal hiztegi batean, hala nola abadegarrizko, abailgarrikiro, abuztukotasun, adamkume, abalhartzaile (abal sarreraren azpisarrera litzateke)…
Eta badira beste asko euskara batuaren grafia betetzen ez dutenak; hau da, lema bakarra behar luketenak bi edo hiru lema gisa agertzen dira. Adibidez: abeltzantza, abeltzaintza, abelzaintza; abantxu, abantzu, abantsu; aberatstasun, aberastazun, aberastasun; aberasgarri, aberatsgarri; abelzain, abeltzain; abelzaingo, abeltzaingo; aberaspide, aberasbide; abandono, abandonu; abangoardia, abanguardia; abangoardismo, abanguardismo, abangoardista, abanguardista; aberaska, abaraska; abaniko, abaniku; abaor, ababor; abantailgarri, abantailagarri… Ez dakit zenbat diren halakoak, baina garbi dago lemak ateratzeko iragazkia ez dagoela behar bezain doitua (euskara batuaren lemak atera nahi badira, behintzat).
Horren ondorioz, 91.884 lema horiek ez dira denak benetako lema. Gainera, gorago azaldutako erlazio asintotikoaren arabera, Elhuyarren CE corpusak, bere 125 milioi hitzekin, 75.000 lema inguru baditu, EHUren ETC corpusak, bere 270 milioi hitzekin, 75.000 lema baino gehiago izan behar ditu, bai, baina ez % 22,5 gehiago.
Konklusioa. Esan genezake, bekatu handirik egin gabe, gaur egungo euskarak 80.000 hitz (lema) inguru dituela. Hala ere, hasieran esan bezala, galdera bezain eskasa izan daiteke erantzuna.
Beste kontu bat da zenbat hitz erabiltzen ditugun egunerokoan. Batzuek aski dute 1.000 hitzekin; hiztun alfabetatu batek 3.000-4.000 erabiltzen ditu, nonbait. Eta ezagutu? Kultura jasoko euskaldun alfabetatu batek 20.000 hitz ezagut ditzake, edo 25.000, oso «berbafiloa» bada (oraintxe asmatu dut hitz hori; ea noiz ikusten dugun corpusetan).
Zenbat hitz ditu euskarak? Asko, zuk nahi dituzun guztiak, maitea.
_________________
[1] Eskerrik asko Elhuyarreko Hizkuntza Teknologien Saileko Iker Manterolari, emandako informazioagatik.
